Someone please help!!! will give brainliest!!!
Round your answer to the nearest hundredths, if necessary.
Find the surface area of the figure
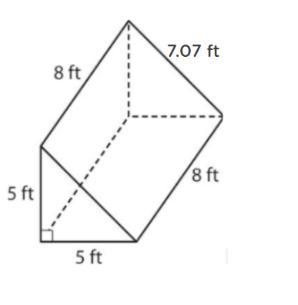
Answers
Answer:161.56
Step-by-step explanation:
8 x5=40
8 x 7.07=56.56
1/2 x 5 x 5 x 2= 25
8 x 5=40
Add that all together
Related Questions
The Fast Repair Shop charges a $25 fee plus $30 an hour for labor. Write the equation for the cost of the repair job, y, if the repair job took x hours.
Answers
Answer:
y=30x+25
Step-by-step explanation:
y=mx+b (slope-intercept formula)
y= amount of money per hour of labor
m= 30 (amount per hour, slope)
b= 25 (y-intercept, starting rate)
Can someone please help me answer this question asap thank you
Answers
Classify the following non-identity isometries of R? If the isometry is not unique, justify all possibilities. (a) Let / be an isometry, without fixed points, given by a reflection followed by a glide reflection (b) Let y be an isometry that fixes two points, g(P) = P and 9(Q) = Q.
Answers
(a) The non-identity isometry given by a reflection followed by a glide reflection can be classified as a translation. In Euclidean geometry, any reflection followed by a glide reflection is equivalent to a translation in a specific direction.
(b) The non-identity isometry that fixes two points can be classified as a rotation. In Euclidean geometry, any isometry that fixes two distinct points is a rotation about the midpoint between those two points.
(a) Let's denote the reflection as R and the glide reflection as G. If G is applied after R, we have GR. Since the isometry does not have any fixed points, GR cannot be a reflection or a translation. Therefore, the only possibility left is that GR is a glide reflection. However, in Euclidean geometry, a glide reflection is equivalent to a translation. Hence, the non-identity isometry in this case is a translation.
(b) Since the isometry fixes two points P and Q, let's denote the isometry as F. Fixing two distinct points implies that the isometry must be a rotation about the midpoint between those two points. Therefore, the non-identity isometry in this case is a rotation.
In summary, the non-identity isometry in (a) is a translation, and the non-identity isometry in (b) is a rotation.
Learn more about Euclidean geometry here: brainly.com/question/31120908
#SPJ11
25% of all college students major in STEM (Science, Technology, Engineering, and Math). If 34 college students are randomly selected, find the probability that exactly 7 of them major in STEM. Round to 4 decimal places. 64% of all students at a college still need to take another math class. If 4 students are randomly selected, find the probability that a. Exactly 2 of them need to take another math class. 0.3186 b. At most 2 of them need to take another math class. 0.0997 X c. At least 2 of them need to take another math class. 0.9537 X d. Between 2 and 3 (including 2 and 3) of them need to take another math class. 0.9829 x Round all answers to 4 decimal places. About 4% of the population has a particular genetic mutation. 600 people are randomly selected. Find the mean for the number of people with the genetic mutation in such groups of 600. (Round to 2 decimal places if possible.) About 8% of the population has a particular genetic mutation. 200 people are randomly selected. Find the standard deviation for the number of people with the genetic mutation in such groups of 200. (If possible, round to 1 decimal place.) Question Help: . Written Example
Answers
1. Probability of exactly 7 students majoring in STEM: is 0.1312
2. Probability of exactly 2 students needing another math class: is 0.3186
3. Probability of at most 2 students needing another math class: 0.0997
4. Probability of at least 2 students needing another math class: 0.9537
5. Probability of between 2 and 3 students needing another math class: 0.9829
6. Mean for the number of people with the genetic mutation: 24
7. Standard deviation for the number of people with the genetic mutation: 4.49
1. Probability of exactly 7 students majoring in STEM:
The probability of exactly 7 students majoring in STEM can be calculated using the binomial probability formula:
P(X = k) = (nCk) × ([tex]p^k[/tex]) × ([tex](1-p)^{(n-k)[/tex])
Where:
n = Total number of trials (34)
k = Number of successful trials (7)
p = Probability of success (25% or 0.25)
Plugging in the values:
P(X = 7) = (34C7) × ([tex]0.25^7[/tex]) × ([tex](1-0.25)^{(34-7)[/tex])
Using a calculator or statistical software, calculate P(X = 7) = 0.1312 (rounded to 4 decimal places).
2. Probability of exactly 2 students needing another math class:
The probability of exactly 2 students needing another math class can be calculated using the binomial probability formula:
P(X = k) = (nCk) × ([tex]p^k[/tex]) × ([tex](1-p)^{(n-k)[/tex])
Where:
n = Total number of trials (4)
k = Number of successful trials (2)
p = Probability of success (64% or 0.64)
Plugging in the values:
P(X = 2) = (4C2) × (0.64²) × ([tex](1-0.64)^{(4-2)[/tex])
Using a calculator or statistical software, calculate P(X = 2) = 0.3186 (rounded to 4 decimal places).
3. Probability of at most 2 students needing another math class:
To calculate the probability of at most 2 students needing another math class, we sum up the probabilities of exactly 0, 1, and 2 students needing another math class:
P(X ≤ 2) = P(X = 0) + P(X = 1) + P(X = 2)
Using the binomial probability formula as in the previous steps, calculate P(X ≤ 2) = 0.0997 (rounded to 4 decimal places).
4. Probability of at least 2 students needing another math class:
To calculate the probability of at least 2 students needing another math class, we subtract the probability of 0 students needing another math class from 1:
P(X ≥ 2) = 1 - P(X = 0)
Using the binomial probability formula, calculate P(X ≥ 2) = 0.9537 (rounded to 4 decimal places).
5. Probability of between 2 and 3 students needing another math class:
To calculate the probability of between 2 and 3 students needing another math class (inclusive), we sum up the probabilities of exactly 2 and exactly 3 students needing another math class:
P(2 ≤ X ≤ 3) = P(X = 2) + P(X = 3)
Using the binomial probability formula, calculate P(2 ≤ X ≤ 3) = 0.9829 (rounded to 4 decimal places).
6. Mean for the number of people with the genetic mutation:
The mean for the number of people with the genetic mutation can be calculated using the formula:
Mean = n × p
Where:
n = Total number of trials (600)
p = Probability of success (4% or 0.04)
Plugging in the values, calculate the mean = 600 × 0.04 = 24 (rounded to 2 decimal places).
7. Standard deviation for the number of people with the genetic mutation:
The standard deviation for the number of people with the genetic mutation can be calculated using the formula:
Standard deviation = √(n × p × (1 - p))
Where:
n = Total number of trials (200)
p = Probability of success (8% or 0.08)
Plugging in the values, calculate the standard deviation = √(200 × 0.08 × (1 - 0.08)) = 4.49 (rounded to 1 decimal place).
So, the mean for the number of people with the genetic mutation in groups of 600 is 24, and the standard deviation for the number of people with the genetic mutation in groups of 200 is 4.49.
Learn more about probability at
https://brainly.com/question/31828911
#SPJ4
Given that is a random variable having a Poisson distribution, compute the following: (a) P(x = 1) when μ = 3.5 -0 P(x) = (b) P(x ≤ 9)when μ = 6 P(x) = (c) P(x > 2) when μ = 3 P(x) = (d) P(x < 1) when μ = 2.5 P(x) =
Answers
P(x < 1) = 0.082085.
The given parameters are μ and x. The mean and variance of the Poisson distribution are μ and σ^2 = μ.The probability that the random variable X takes on the value x is given by P(x).P(x=1) when μ = 3.5
Here, x = 1 and μ = 3.5Plug in the given values in the Poisson distribution,
P(x = 1) = ((e^-3.5) (3.5^1))/1!P(x = 1) = ((0.0301974) (3.5))/1!P(x = 1) = 0.105691(1)P(x = 1) = 0.105691
Thus, P(x=1) = 0.105691.P(x ≤ 9)when μ = 6. The given parameters are μ and x. The mean and variance of the Poisson distribution are μ and σ^2 = μ.
P(x ≤ 9) when μ = 6. Here, x ≤ 9 and μ = 6
Using the Poisson formula:
P(x ≤ 9) = Σ P(x = i) for i = 0 to 9.P(x ≤ 9) = Σ P(x = i) for i = 0 to 9.P(x ≤ 9) = Σ ((e^-6)(6^i))/i! for i = 0 to 9P(x ≤ 9) = 0.091578So,
P(x ≤ 9) = 0.091578P(x > 2) when μ = 3.The mean and variance of the Poisson distribution are μ and σ^2 = μ.P(x > 2) when μ = 3:Here, x > 2 and μ = 3
Using the Poisson formula:
P(x > 2) = Σ P(x = i) for i = 3 to infinityP(x > 2) = Σ ((e^-3) (3^i))/i! for i = 3 to infinityP(x > 2) = 1 - P(x ≤ 2)P(x > 2) = 1 - ((e^-3)(3^0))/0! + ((e^-3) (3^1))/1! + ((e^-3) (3^2))/2!P(x > 2) = 1 - ((0.04978706836)(1))/1 + ((0.04978706836)(3))/1 + ((0.04978706836)(9))/2P(x > 2) = 1 - (0.04978706836 + 0.1493612051 + 0.2240418077)P(x > 2) = 0.5768099198So, P(x > 2) = 0.5768099198.P(x < 1) when μ = 2.5.
The given parameters are μ and x. The mean and variance of the Poisson distribution are μ and σ^2 = μ.P(x < 1) when μ = 2.5:Here, x < 1 and μ = 2.5
Using the Poisson formula:
P(x < 1) = P(x = 0)P(x < 1) = ((e^-2.5) (2.5^0))/0!P(x < 1) = 0.082085P(x < 1) = 0.082085Thus, P(x < 1) = 0.082085.
To know more about Poisson formula, visit:
https://brainly.com/question/31967309
#SPJ11
Given that X is a random variable having a Poisson distribution, the probability mass function of X is [tex]P(x)=((e^{-\mu})(\mu^{x}))/x![/tex],
x=0,1,2,…
Here, μ is the mean or the expected value of the distribution.
a) P(x=1) when μ=3.5 is 0.1288 (approx.)
b) P(x≤9) when μ=6 is 0.99988 (approx.)
c) P(x>2) when μ=3 is 0.5766 (approx.)
d) P(x<1) when μ=2.5 is 0.0821 (approx.).
Compute the following:
a) P(x=1) when μ=3.5
Calculate probability for random variable by using the probability mass function of X as follows:
[tex]P(x=1)=((e^{-3.5})(3.5^{1}))/1![/tex]
=0.1288 (approx.)
b) P(x≤9) when μ=6
Calculate, [tex]P(x\leq9)= \sum P(x=k)[/tex] from
k=0 to
[tex]9= \sum ((e^{-6})(6^{k}))/k![/tex] from
k=0 to
9=0.99988 (approx.)
c) P(x>2) when μ=3
We are given μ=3. Then,
P(x>2)= 1- P(x≤2)
= 1- (P(x=0)+P(x=1)+P(x=2))
[tex]= 1- (((e^{-3})(3^{0}))/0!+((e^{-3})(3^{1}))/1!+((e^{-3})(3^{2}))/2!)[/tex]
= 0.5766 (approx.)
d) P(x<1) when μ=2.5
Then, P(x<1)=
P(x=0)
[tex]= ((e^{-2.5})(2.5^0))/0![/tex]
= 0.0821 (approx.)
To know more about probability visit
https://brainly.com/question/32004014
#SPJ11
Which of the following scatterplots do not show a clear relationship and would not have a trend line?
Answers
Answer:
B
Step-by-step explanation:
The graph does not form a obvious line and therefore is the answer.
Answer:
The answer is B i got it right.
Step-by-step explanation:
Find the value of x. Also with explanation please
Answers
Answer:
x+90°+130°=360°
x+220°=360°
x=360°-220°
x=140°
A robot moves 3\text{ m}3 m3, start text, space, m, end text, turns more than 90\degree90°90, degree clockwise, moves 4\text{ m}4 m4, start text, space, m, end text more, turns clockwise again, then moves 3.6\,\text{m}3.6m3, point, 6, start text, m, end text. The robot ends where it started, as shown.
How far did the robot turn the first time?
Do not round during your calculations. Round your final answer to the nearest degree.
Answers
Answer:120
Step-by-step explanation:
Answer:
120
Step-by-step explanation:
khan
why did the german soilders let the prisoners sing while they were marching? PLSSS HELP ILL MARK BRAILIEST. if u give a link i will not so don’t even try :). pls help!!!!
Answers
Find the value of x. Enter your answer as a number
Answers
Then 360-280=80 degrees
Which of the following statement(s) is/are TRUE about the number of data values that lie over an interval for normal distribution by using the empirical rule ? There are 71.5% data values within 1 -- and u +20. There are 68% data values within y and pto. There are 50% data values within and o. There are 50% data values within u-30 and . There are 100% data values within 30 and + 30.
Answers
The statement "There are 68% data values within μ and μ+σ" is true. (option b).
The empirical rule states that approximately 68% of data values in a normal distribution lie within one standard deviation (σ) of the mean (μ). This means that if we consider the interval from μ to μ+σ, it will contain roughly 68% of the data values.
In summary, among the given statements, only statement b) is true. The empirical rule helps us understand the distribution of data values based on their distance from the mean (μ) in a normal distribution. It is important to remember that the rule provides approximate percentages and does not provide precise values for specific intervals.
To know more about normal distribution here
https://brainly.com/question/31226766
#SPJ4
Complete Question:
Which of the following statement(s) is/are TRUE about the number of data values that lie over an interval for normal distribution by using the empirical rule?
a) There are 71.5% data values within μ-σ and μ+20.
b) There are 68% data values within μ and μ+σ.
c) There are 50% data values within μ and ∞.
d) There are 50% data values within µ - 30 and μ.
e) There are 100% data values within μ-30 and μ+30.
Do dilations always produce congruent figures
Answers
Answer:
No, sometimes it can just produce a similar image .
Can I get brainliest?
Step-by-step explanation:
Wesley walked 11 miles in 4 hours. If he walked the same distance every hour, how far did he walk in one hour? Using only feet
Answers
Answer:
14,520
Step-by-step explanation:
The computation is shown below:
Given that
Wesley walked 11 miles in 4 hours
Now we can say that
1 miles = 5280
So, 11 miles would be
= 5280 × 11
= 58,080
And, the number of hours is 4
So, for one hour he would be far of
= 58,080 ÷ 4
= 14,520
I need to know what is the find m<ACD
Answers
Answer:
28
Step-by-step explanation:
if (AB and DC) parallels lines than the equation is alternate interior and therefore congruent to each other
28 because they are equall
Please help now
What is the value of A when we rewrite 3^x as A^5x
Answers
Answer:
A=3^1/5
Step-by-step explanation:
3^x = 3 ^ 1/5*3^5x. Basically you need 3^x to equal A^x. A^x is equal to A^5x in this situration. So, multiply 5x to equal 1x. To make 1x you need to multiply the 5x by 1/5. So, the A value is 3, since the whole number in the 3^x has to be equal to the whole number in A^x. Knowing this, we can tell that A must be equal to 3^1/5.
Answer:
3^1/5
The complex numbers $z$ and $w$ satisfy $|z| = |w| = 1$ and $zw \ne -1.$
(Prove that $\overline{z} = \frac{1}{z}$ and $\overline{w} = \frac{1}{w}.$
Answers
Step-by-step explanation:
I can't read any of the things they are all in code :( I can answer the question in the comments. Also what is ne. I am so sorry!
Please help no links please
Answers
explain
Answer:
9/20
Step-by-step explanation:
A study was done to see if males or females are more stressed at work. The question asked respondents to indicate their level of stress at work (not at all, somewhat, very). In order to determine if there is an association between gender and stress level at work, the appropriate test is
paired t test
t test for two independent samples
correlation
Chi Square test for independence
one-way ANOVA
Answers
The appropriate test to determine the association between gender and stress level at work is the Chi-Square test for independence.
The Chi-Square test for independence is used when we have categorical variables and want to determine if there is an association or relationship between them. In this case, the variables are gender (male or female) and stress level at work (not at all, somewhat, very).
The test will help us determine if there is a significant association between gender and stress level at work, or if any observed differences are due to chance.
To perform the Chi-Square test, we first need to organize the data into a contingency table, which shows the frequencies or counts of each combination of gender and stress level. We then calculate the expected frequencies under the assumption of independence between the variables.
The Chi-Square test statistic is calculated by comparing the observed and expected frequencies. Finally, we compare the test statistic to the critical value from the Chi-Square distribution with the appropriate degrees of freedom to determine if the association is statistically significant.
In summary, to determine if there is an association between gender and stress level at work, the appropriate test is the Chi-Square test for independence. This test will help us understand if there is a significant relationship between these variables or if any observed differences are due to chance.
To know more about the Chi-Square test refer here:
https://brainly.com/question/28348441#
#SPJ11
Function notation ? G (x)=x-3 ; find g(-6) .. how do I answer this?
Answers
Answer:
The value of g(-6) will be "-9".
Step-by-step explanation:
The given function is:
⇒ [tex]g(x)=x-3[/tex]
then,
⇒ [tex]g(-f)=?[/tex]
On putting the value "-6" at the place of "x", then we get
⇒ [tex]g(-6) = (-6)-3[/tex]
⇒ [tex]=-6-3[/tex]
⇒ [tex]=-9[/tex]
Thus the above is the correct solution.
Find the quadratic least squares approximation to the function f(x) = = e* on (0,2).
Answers
The quadratic least squares approximation to f(x) = eˣ on the interval [0,2] is g(x) = (e - 1)x + 1.
Let's choose x = 0, x = 1, and x = 2.
The corresponding y-values will be y = f(0) = e⁰ = 1,
y = f(1) = e¹ = e, and
y = f(2) = e².
Now, we can set up a system of equations using the chosen data points and solve for the coefficients a, b, and c:
For x = 0:
a(0)² + b(0) + c = 1
c = 1
For x = 1:
a(1)²+ b(1) + c = e
a + b + c = e
For x = 2:
a(2)² + b(2) + c = e²
4a + 2b + c = e²
Substituting c = 1 from equation 1 into equations 2 and 3, we have:
a + b + 1 = e
4a + 2b + 1 = e²
Now, we can solve this system of equations to find the values of a and b.
Subtracting equation 2 from equation 3, we get:
4a + 2b + 1 - (a + b + 1) = e² - e
3a + b = e² - e
Substituting b = e - a - 1 into equation 2, we have:
a + (e - a - 1) + 1 = e
e - a = e
a = 0
Substituting a = 0 into equation 2, we get:
b + 1 = e
b = e - 1
Therefore, the quadratic least squares approximation is given by:
g(x) = ax² + bx + c
= (0)x² + (e - 1)x + 1
= (e - 1)x + 1
To learn more on Quadratic least squares click:
https://brainly.com/question/30546090
#SPJ4
how many ways are there to choose a president, vice president, and treasurer of a 7- member club, if no person can hold more than one oce?
Answers
There are 210 ways to choose a president, vice president, and treasurer for a 7-member club, with no person holding more than one office. Each position can be filled by a different member, resulting in 210 unique combinations.
To determine the number of ways to choose the three positions, we can use the concept of permutations. The president can be selected from the 7 members in 7 different ways. Once the president is chosen, there are 6 remaining members to choose from for the position of vice president. Therefore, there are 6 choices for the vice president. Finally, the treasurer can be chosen from the remaining 5 members.
To calculate the total number of ways, we multiply the number of choices for each position:
7 * 6 * 5 = 210.
Hence, there are 210 ways to choose a president, vice president, and treasurer from a 7-member club, with the condition that no person can hold more than one office.
In summary, the answer is that there are 210 ways to select the president, vice president, and treasurer for the 7-member club, with each member occupying only one position.
To learn more about permutations, visit:
https://brainly.com/question/1216161
#SPJ11
Work out 5/6 x 3/4
Give the answer as a fraction in its simplest form.
Answers
Answer:
The answer is 5/8
Step-by-step explanation:
Measurement of inspection time, from a large sample of outsourced components, gave the following distribution:
Time (seconds)
20
22
24
25
27
28
29
31
Number (individual data 2 )
1
3
4
4
2
4
3
3
Calculate Product moment correlation coefficient
Determine the equation of the least squares regression line of the number of components on time.
Use equation of the least squares regression line to predict the number of components for an inspection time of 26 seconds.
Task 1.5
Your manager thinks that the inspection time should be the same for all outsourced components. Using the data
provided test (at the 5% significance level) this hypothesis and indicate whether there is a correlation or not.
Task 1.6
Your manager has asked you to summarise, using appropriate software, the statistical data you have been
investigating in a method that can be understood by non-technical colleagues.
Answers
Task 1.1 To calculate the product moment correlation coefficient, first we need to find the means of both data sets. The mean of the time is:
$$\bar{t} = \frac {20+22+24+25+27+28+29+31}{8} = 25.25$$
The mean of the number is: $$\bar{n} = \frac {1+3+4+4+2+4+3+3}{8} = 3$$Next, we need to find the standard deviation of both data sets.
We will use the following formulas: $$s_t = \sqrt {\frac {\sum (t - \bar{t2} {n-1}} $$$$s_n = \sqrt{\frac {\sum (n - \bar{n2} {n-1}} $$
Using these formulas, we find that the standard deviation of the time is approximately 4.172 and the standard deviation of the number is approximately 1.247.
Using the following formula to calculate the product moment correlation coefficient:
$r = \frac{\sum (t - \bar{t})(n - \bar{n})}{(n - 1)s_t s_n}$$r = \frac{(20-25.25)(1-3)+(22-25.25)(3-3)+(24-25.25)(4-3)+(25-25.25)(4-3)+(27-25.25)(2-3)+(28-25.25)(4-3)+(29-25.25)(3-3)+(31-25.25)(3-3)}{7(4.172)(1.247)}$$r = \frac{-7.5+1.5-1.245-0.25+2.205+1.215+3.465+2.995}{35.531} \approx. 0.521$
Therefore, the product moment correlation coefficient is approximately 0.521.
Task 1.2 The equation of the least squares regression line of the number of components on time can be found using the following formulas: $$b = \frac {\sum (t - \bar{t}) (n - \bar{n})} {\sum (t - \bar{t}) ^2} $$$$a = \bar{n} - b \bar{t}$$
Using these formulas, we find that: $$b = \frac{(20-25.25)(1-3)+(22-25.25)(3-3)+(24-25.25)(4-3)+(25-25.25)(4-3)+(27-25.25)(2-3)+(28-25.25)(4-3)+(29-25.25)(3-3)+(31-25.25)(3-3)}{\sum (t - \bar{t})^2}$$$$b \approx. -0.235$$$$a = \bar{n} - b \bar{t}$$$$a \approx. 8.439$$
Therefore, the equation of the least squares regression line of the number of components on time is: $$n = 8.439 - 0.235t$$
Task 1.3Using the equation of the least squares regression line, we can predict the number of components for an inspection time of 26 seconds. $$n = 8.439 - 0.235t$$$$n = 8.439 - 0.235(26) $$$$n \approx. 2.974$$
Therefore, we predict that the number of components for an inspection time of 26 seconds is approximately 2.974.
Task 1.4 To test the hypothesis that the inspection time should be the same for all outsourced components, we can use a one-way ANOVA test. We can set up the null hypothesis as follows: H0: μ1 = μ2 = μ3 = μ4 = μ5 = μ6 = μ7 = μ8where μi is the mean inspection time for the ith group of components, and the alternative hypothesis as follows: Ha: At least one mean is different
Using an ANOVA calculator, we find that the F-statistic is approximately 12.04 and the p-value is approximately 0.00036. Since this p-value is less than the significance level of 0.05, we reject the null hypothesis and conclude that there is evidence to suggest that at least one mean is different. Therefore, we can say that there is a correlation between inspection time and the number of components.
Task 1.5 To summarize the statistical data for non-technical colleagues, we can create a table or graph that displays the distribution of inspection times and the corresponding number of components. We can also include the mean, standard deviation, and correlation coefficient to provide a summary of the relationship between the two variables. Additionally, we can use the equation of the least squares regression line to make predictions about the number of components for different inspection times, which can help inform decision-making.
To know more about standard deviation refer to:
https://brainly.com/question/475676
#SPJ11
You recently completed an experiment concerning the effects of carbs on happiness. One group of 11 people are assigned a high carb diet, another group of 11 people are assigned a moderate-high carb diet, another group of 11 people are assigned a moderate-low carb diet, and a final group of 11 people are assigned a low carb diet. If I find that I fail to reject the null hypothesis, what might my next step be? O Change my analysis and alpha to make the finding significant and then run post-hoc tests. O Run multiple dependent measures t-tests to see if there are any significant differences between particular groups O Run multiple independent samples t-tests to see if there are any significant differences between particular groups Change my hypothesis to see if I can find something significant with a different hypothesis for this study Run home and binge-watch Bridgerton because there is nothing else that should be done statistically
Answers
If you fail to reject the null hypothesis in your experiment, indicating that there is no significant difference between the groups, there are several potential next steps you can consider. The appropriate next step depends on the specific goals and context of your study. Here are a few options:
Refine your analysis and adjust the alpha level: You can re-evaluate your statistical analysis and check if there are any potential issues or mistakes that could have influenced the results. You can also consider adjusting the significance level (alpha) to increase the chance of detecting significant differences if you believe it is justified. However, be cautious with this approach as it may increase the risk of Type I errors (false positives).
Conduct post-hoc tests or further analyses: If the overall analysis did not yield significant results, you can explore further by conducting post-hoc tests or additional analyses. This could involve comparing specific pairs of groups to identify any potential significant differences or examining other variables or dependent measures that may have an impact on the outcome.
Modify or reframe your hypothesis: If the results do not support your initial hypothesis, you may need to reconsider your hypothesis or research question. Explore alternative explanations, variables, or factors that could be influencing the outcome. This could involve formulating new hypotheses or exploring different angles for your study.
Review and refine your study design: Take a closer look at your experimental design, sample size, data collection methods, or other aspects of your study. Identify potential limitations or areas for improvement, and consider making adjustments or modifications for future studies.
Seek expert guidance or consultation: If you are uncertain about the next steps or need further guidance, it can be helpful to consult with experts or colleagues in your field. They may provide valuable insights and suggestions based on their expertise and experience.
In any case, it's important to approach the results objectively and make informed decisions based on the specific context and goals of your study.
Learn more about hypothesis problem here:
https://brainly.com/question/15980493
#SPJ11
Consider the differential equation: xy" – 9 xy = x?e3x A) [5 points] Solve the associated homogeneous differential equation. B) (15 points] Solve the given differential equation by using variation of parameters. Question 2 [20 pts): A) [10 points) Find e{[e31–5) (3, 0 St<5 B) (10 points) Evaluate the Laplace Transform of the function f(t) = (231-5), t25 Question 3 (20 pts): Consider the Initial Value Problem: y"+2 y' - 3 y=9, yO=0, Y'O=5. A) [10 points] Use Laplace Transform to evaluate Y(s). B) (10 points] Solve the given Initial Value Problem
Answers
The general solution to the given differential equation using variation of parameters is:
[tex]y(x) = (-1/6x - 1/36 + c_5 + c_6e^{-6x})e^{3x} + (1/6x - 1/36 + c_7 + c_8e^{6x})e^{-3x}[/tex]
Question 1:
A) To solve the associated homogeneous differential equation, we consider xy" - 9xy = 0.
Dividing through by x gives us y" - 9y = 0, which is a second-order linear homogeneous differential equation with constant coefficients.
The characteristic equation is [tex]r^2 - 9 = 0[/tex].
Solving this equation, we find two roots: r = 3 and r = -3.
Therefore, the general solution to the homogeneous differential equation is [tex]y(x) = c_1e^{3x} + c_2e^{-3x}[/tex], where [tex]c_1[/tex] and [tex]c_2[/tex] are arbitrary constants.
B) To solve the given differential equation using variation of parameters, we assume the particular solution has the form [tex]y_p(x) = u_1(x)e^{3x} + u_2(x)e^{-3x}[/tex], where [tex]u_1(x)[/tex] and [tex]u_2(x)[/tex] are functions to be determined.
We find the derivatives of [tex]y_p(x)[/tex]:
[tex]y_p'(x) = u_1'(x)e^{3x} + u_2'(x)e^{-3x} + 3u_1(x)e^{3x} - 3u_2(x)e^{-3x}\\y_p''(x) = u_1''(x)e^{3x} + u_2''(x)e^{-3x} + 6u_1'(x)e^{3x} - 6u_2'(x)e^{-3x} + 9u_1(x)e^{3x} + 9u_2(x)e^{-3x}[/tex]
Substituting these expressions into the given differential equation, we have:
[tex]x(u_1''(x)e^{3x} + u_2''(x)e^{-3x} + 6u_1'(x)e^{3x} - 6u_2'(x)e^{-3x} + 9u_1(x)e^(3x) + 9u_2(x)e^{-3x}) - 9x(u_1(x)e^{3x} + u_2(x)e^{-3x}) = xe^{3x}[/tex]
Simplifying and collecting terms, we get:
[tex]x(u_1''(x)e^{3x} + u2''(x)e^{-3x}) + 6x(u_1'{x}e^{3x} - u_2'(x)e^{-3x}) = xe^{3x}[/tex]
To solve for [tex]u_1'(x)[/tex] and [tex]u_2'(x)[/tex], we equate coefficients of [tex]e^{3x}[/tex] and [tex]e^{-3x}[/tex] separately.
For the coefficient of [tex]e^{3x}[/tex]:
[tex]u_1''(x) + 6u_1'(x) = 1[/tex]
The auxiliary equation is r^2 + 6r = 0, with roots r = 0 and r = -6.
The complementary solution is [tex]u_1_c(x) = c_3 + c_4e^{-6x}[/tex], where [tex]c_3[/tex] and [tex]c_4[/tex] are arbitrary constants.
Using the method of variation of parameters, we assume [tex]u_1{x} = v_1(x)e^{-6x}[/tex], where [tex]v_1(x)[/tex] is a new unknown function.
We find [tex]u_1'(x) = v_1'(x)e^{-6x} - 6v_1(x)e^{-6x}[/tex].
Substituting these expressions back into the differential equation, we have:
[tex]v_1''(x)e^{-6x} - 12v_1'(x)e^{-6x} + 6v_1'(x)e^{-6x} - 36v_1(x)e^{-6x} = 1[/tex]
Simplifying, we get:
[tex]v1''(x)e^{-6x} - 6v1(x)e^{-6x} = 1[/tex]
To solve for v1'(x), we integrate both sides with respect to x:
∫[tex](v_1''(x)e^{-6x} - 6v_1(x)e^{-6x})dx[/tex] = ∫(1)dx
This gives us:
[tex]v_1'(x)e^{-6x} + 6v_1(x)e^{-6x} = x + c_5[/tex], where [tex]c_5[/tex] is an arbitrary constant.
Using integration by parts on the left-hand side, we have:
[tex]v_1(x)e^{-6x} = -1/6xe^{6x} - (1/36)e^{6x} + c_5e^{6x} + c_6[/tex], where [tex]c_6[/tex] is another arbitrary constant.
Therefore, the solution for the coefficient of [tex]e^{3x}[/tex] is:
[tex]u_1(x) = (-1/6x - 1/36 + c_5)e^{3x} + c_6e^{-3x}[/tex]
Similarly, for the coefficient of e^(-3x), we have:
[tex]u_2(x) = (1/6x - 1/36 + c7)e^{-3x} + c8e^{3x}[/tex], where c7 and c8 are arbitrary constants.
Finally, the particular solution to the given differential equation is:
[tex]y_p(x) = u_1(x)e^{3x} + u_2(x)e^{-3x} \\= ((-1/6x - 1/36 + c_5)e^{3x} + c_6e^{-3x})e^{3x} + ((1/6x - 1/36 + c_7)e^{-3x} + c_8e^{3x})e^{-3x} \\= (-1/6x - 1/36 + c_5 + c_6e^{-6x})e^{3x} + (1/6x - 1/36 + c_7 + c_8e^{6x})e^{-3x}[/tex]
This is the general solution to the given differential equation using variation of parameters.
To know more about general solution, refer here:
https://brainly.com/question/32062078
#SPJ4
Explain me how to get the answer plsss
Answers
348.1 = 331.3 + 0.6T
subtract 331.3 from both sides
17 = 0.6T
Divide 0.6 from both sides
28.3 (rounded) = T
28 degrees Celsius is the closest answer
A bus route takes about 45 minutes. One driver's times for 9 runs of the route are shown.
Times to Complete Bus Router (min)
44.6 44.8 45.0 44.7 44.6 44.9 44.8 44.8 45.0
Calculate the mean of the bus times.
The mean time for this driver to complete the route was
minutes.
Answers
Test test the daim that the proportion of children from the low income group that did well on the test is different than the proportion of the high income group. Test at the 0.05 significance level. We are given that 24 of 40 children in the low income group did well, and 12 of 35 did in the high income group. If we use L to denote the low income group and H to denote the high income group, identify the correct alternative hypothesis.
Answers
The correct alternative hypothesis is:
Ha: The proportion of children from the low-income group that did well on the test is not equal to the proportion of the high-income group who did well on the test.
The alternative hypothesis is what the researcher wants to test.
It is the opposite of the null hypothesis.
In other words, if the null hypothesis is rejected, the alternative hypothesis is accepted.
The null hypothesis (H0) states that there is no significant difference between the proportions of children from the low income group and the high income group who did well on the test.
The alternative hypothesis (Ha) states that there is a significant difference between the proportions of children from the low income group and the high income group who did well on the test.
Therefore, the correct alternative hypothesis is:
Ha: The proportion of children from the low-income group that did well on the test is not equal to the proportion of the high-income group who did well on the test.
To know more about proportion, visit :
https://brainly.com/question/1496357
#SPJ11
PLEASE ANSWER THIS ASAP
Answers
This is an example of a reflection.
Please help me with this questions please please ASAP ASAP please ASAP help please please ASAP please I'm begging you please please ASAP
Answers
Answer:
3/2
I hope this is correct
Answer:
3/2 = 1.5
Step-by-step explanation:
Find two corresponding sides whose lengths are given.
AB and WX
The scale factor from quad ABCD to quad WXYZ is the ratio of a length in WXYZ to the corresponding length in ABCD.
scale factor = 12/8 = 3/2 = 1.5